
Bloom Filter - Công Cụ Mạnh Mẽ Trong Xử Lý Dữ Liệu

Trong thế kỷ 21, việc xử lý dữ liệu là một phần không thể thiếu của cuộc sống hàng ngày của chúng ta. Tuy nhiên, việc lưu trữ và truy xuất dữ liệu nhanh chóng có thể trở thành một nhiệm vụ phức tạp và đáng tốn kém. Do đó cần có những kỹ thuật tương ứng để đáp ứng được nhu cầu này, cũng là nguyên nhân sự ra đời của Bloom Filter.
Bloom Filter là gì?
Bloom Filter là một cấu trúc dữ liệu được phát triển bởi Burton H. Bloom vào năm 1970, khi ông là một nhà nghiên cứu tại Xerox Corporation's Palo Alto Research Center (PARC). Ông công bố ý tưởng về Bloom Filter trong bài báo "Space/Time Trade-offs in Hash Coding with Allowable Errors" vào năm 1970.
Một trong những điểm quan trọng của Bloom Filter là khả năng kiểm tra sự tồn tại của một phần tử trong một tập hợp lớn mà không cần lưu trữ tất cả các phần tử. Tuy nhiên, Bloom Filter có một số hạn chế quan trọng, bao gồm khả năng false positive (khi Bloom Filter báo rằng một phần tử tồn tại trong tập hợp mặc dù thực tế không có) và không thể loại bỏ phần tử đã thêm vào.
Bloom Filter hoạt động như thế nào?
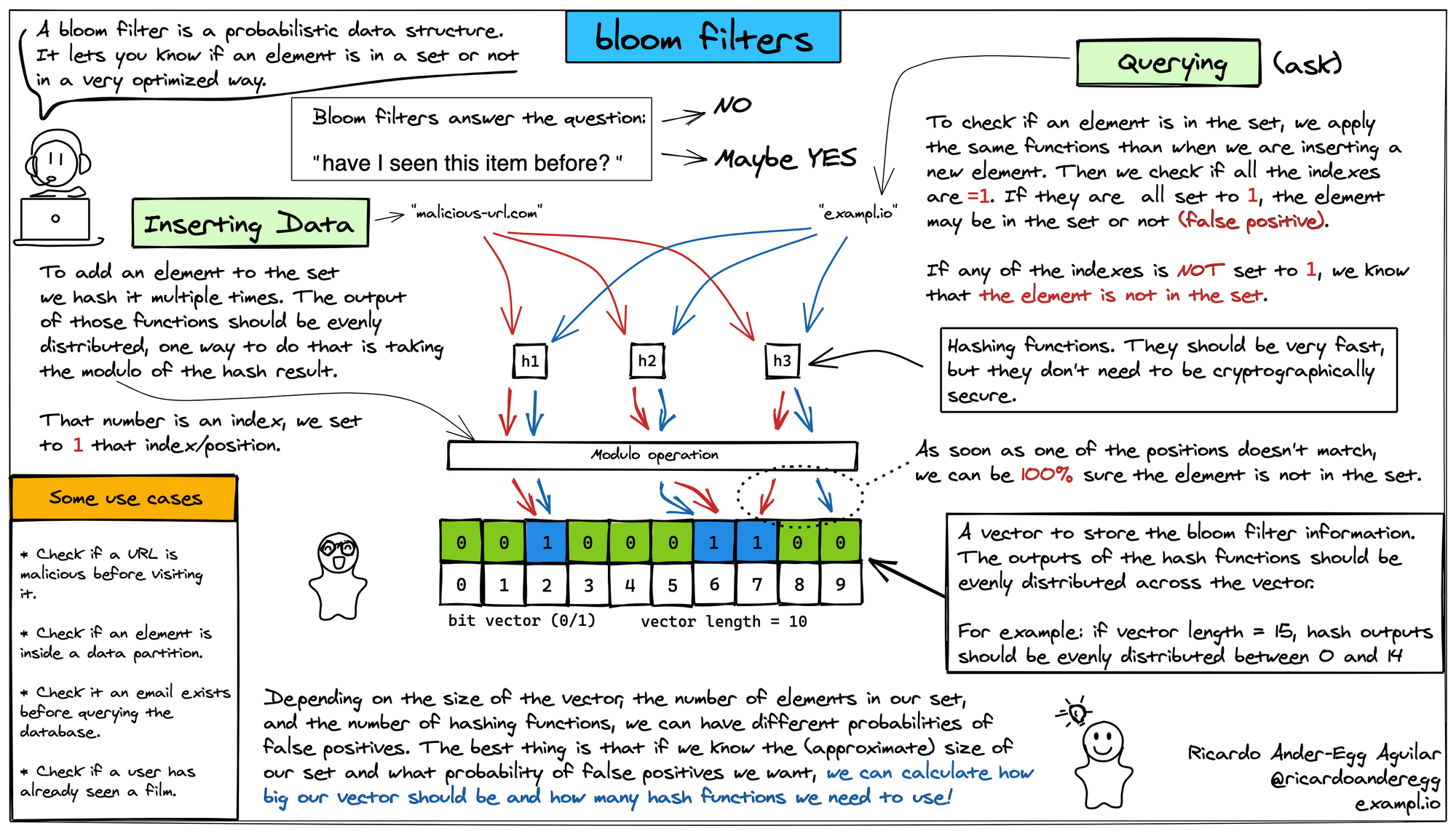
Bloom Filter xuất phát từ nhu cầu tối ưu hóa việc tìm kiếm - khả năng kiểm tra sự tồn tại của một phần tử trong một tập hợp lớn mà không cần lưu trữ tất cả các phần tử. Ý tưởng về cách hoạt động của Bloom Filter có thể mô tả ngắn gọn như sau: Từ giá trị x thuộc tập X, ta tạo ra một giá trị y = h(x) thuộc tập Y, với h là một hash function. Sau đó ta có thể kiểm tra giá trị x' có thuộc X không bằng cách kiểm tra xem y' = h(x') có thuộc tập Y hay không.
Dưới đây ta sẽ giới thiệu chi tiết cách hoạt động:
Khởi tạo Bloom Filter
- Bloom Filter bao gồm một bit array với m bits ban đầu được thiết lập thành giá trị 0.
- Chọn k hash function, mỗi hash function hash một tập giá trị vào m vị trí trên bit array. Tạo nên phân phối xác suất ngẫu nhiên trên mảng.
- Hai tham số quan trọng cần xác định trước khi tạo Bloom Filter là m - kích thước bit array và k số lượng hash function là hai tham số quan trọng cần xác định trước khi tạo Bloom Filter. Hai tham số này tỉ lệ thuận với nhau và tỉ lệ thuận với số lượng phần tử trong tập.
Thêm phần tử vào Bloom Filter
- Khi một phần tử được thêm vào Bloom Filter, ta thực hiện k hash function độc lập thu được k giá trị.
- K giá trị sau khi hash sẽ nằm trong đoạn [0, m-1], tương ứng với các vị trí trên bit array.
- Với mỗi giá trị sau khi hash, ta set bit tại vị trí đó = 1
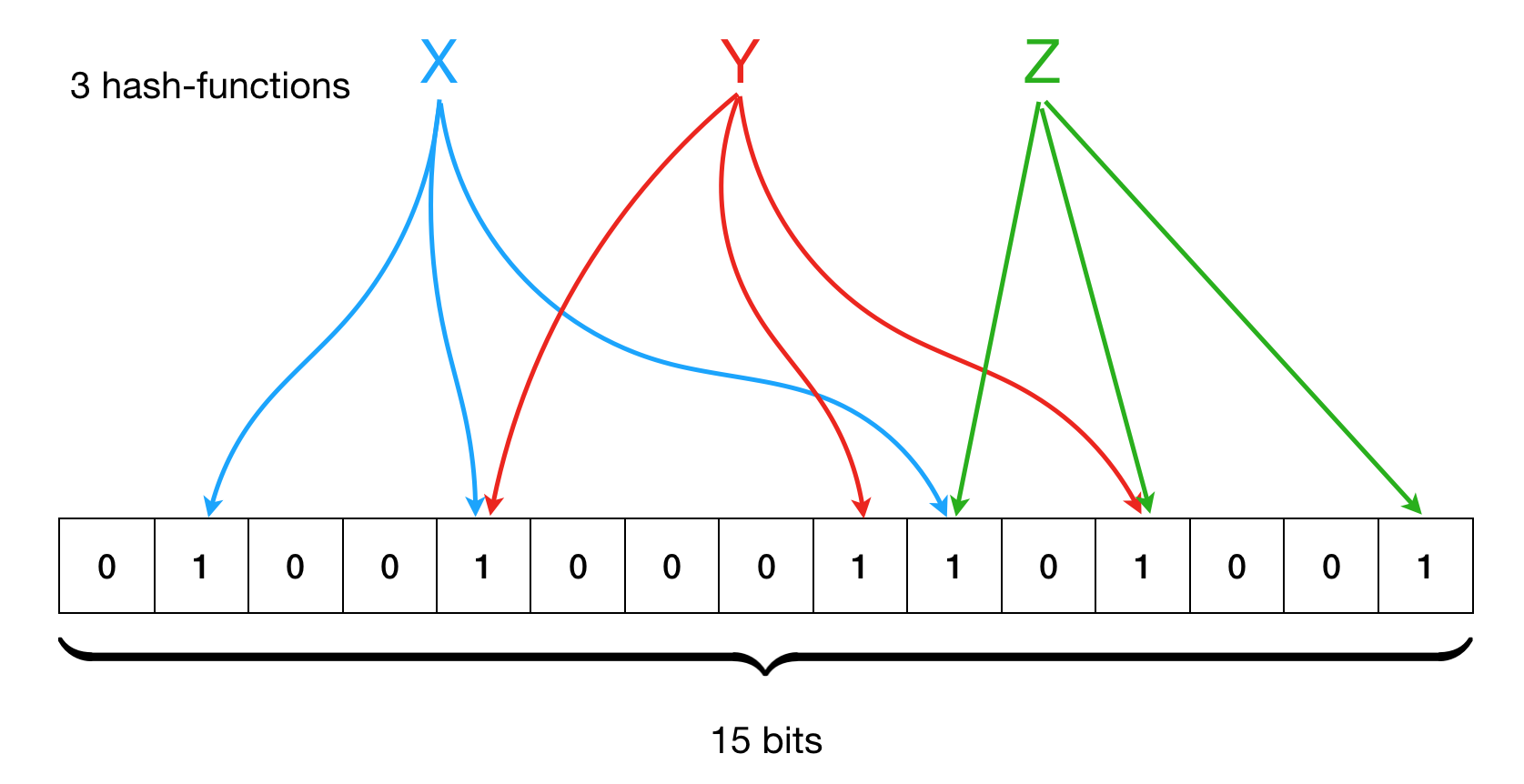
Kiểm tra sự tồn tại của phần tử
- Khi muốn kiểm tra sự tồn tại của một phần tử trong Bloom Filter, ta lặp lại các bước tương tự: thực hiện k hash function và thu được k giá trị tương ứng trong đoạn [0, m-1]
- Kiểm tra k vị trí bit này trong mảng bit. Nếu tất cả các bit ở k vị trí này đều bằng 1. Bloom Filter cho rằng phần tử có thể tồn tại trong tập hợp. (step 3.1)
- Kiểm tra k vị trí bit này trong mảng bit. Nếu ít nhất một vị trí bit là 0, Bloom Filter khẳng định phần tử không tồn tại trong tập hợp. (step 3.2)
False positive
Qua việc tìm hiểu cách hoạt động của Bloom Filter ta có thể thấy rằng. Bloom Filter có thể khẳng định chắc chắn một phần tử không tồn tại trong tập hợp (step 3.2), nhưng ở chiều ngược lại không thể khẳng định chắc chắn là phần tử này thuộc tập hợp (step 3.1). Đây cũng là nhược điểm của Bloom Filter.
- Bloom Filter có khả năng gây ra false positive. Điều này có nghĩa là Bloom Filter có thể báo nhầm rằng một phần tử tồn tại trong tập hợp mặc dù thực tế không có.
- Khả năng false positive tăng lên khi kích thước của bit array (m) nhỏ hoặc số lượng hash function (k) bé. Để giảm false positive, bạn có thể tăng kích thước mảng bit hoặc số lượng hàm băm, nhưng điều này đồng nghĩa với việc tăng sử dụng bộ nhớ và tăng độ phức tạp tính toán.
Immutable
Một trong những đặc tính và cũng là hạn chế của Bloom Filter là không thể thay đổi. Cụ thể ở đây là việc loại bỏ một phần tử ra khỏi tập hợp là không thể, qua cách hoạt động ta có thể thấy không có cách nào loại bỏ phần tử khỏi tập hợp mà vẫn đảm bảo tính chính xác của bit array. Điều này làm cho Bloom Filter thích hợp cho các ứng dụng mà tập hợp dữ liệu là cố định và không thay đổi thường xuyên.
Counting Bloom Filter
Do có những hạn chế như trên. Việc apply trực tiếp Bloom Filter vào các bài toán đặc thù gặp khó khăn, đó cũng là lý do ra đời cho các biến thể. Một trong số đó có thể kể đến là Counting Bloom Filter.
Cho một phần tử x và một tập X. Counting Bloom Filter cho phép truy vấn kiểm tra số lượt xuất hiện trong X của x: cho x và một thresh hold number k. Counting Bloom Filter trả về chắc chắn số tồn tại của x trong X bé hơn k, hoặc có thể lớn hơn hoặc bằng k.
Dễ thấy việc này có thể thực hiện đơn giản thông qua việc thay đổi cách thêm phần tử vào tập. Thay vì set bit = 1 như Bloom Filter, Counting Bloom Filter thêm 1 vào bit. Qua cơ chế trên, việc xoá phần tử ra khỏi tập ban đầu là hoàn toàn có thể. Tuy nhiên việc này cũng gây nên tăng false positive rate khi mà phần tử được xoá không tồn tại không tập ban đầu.
Ngoài ra còn một số biến thể khác của Bloom Filter cũng được sử dụng rộng rãi như:
- Dynamic Bloom Filter: Cho phép thêm và xóa phần tử từ Bloom Filter, phù hợp cho các tình huống cần thay đổi tập dữ liệu thường xuyên.
- Bloomier Filters: Cải tiến của Bloom Filter với khả năng trả lời câu hỏi kiểu "nếu không có dữ liệu này, thì có dữ liệu nào gần giống không?".
Ứng dụng của Bloom Filter trong các bài toán thực tế
Sau khi công bố, Bloom Filter đã tìm thấy nhiều ứng dụng trong thế giới thực và trở thành một công cụ hữu ích trong lĩnh vực xử lý dữ liệu và tối ưu hóa hiệu suất. Nó đã được sử dụng rộng rãi trong các hệ thống cơ sở dữ liệu lớn, lọc thư rác, kiểm tra sự tồn tại của dữ liệu trong bộ nhớ đệm, và nhiều ứng dụng khác.
Cache filtering
Các hệ thống CDN caching web content đến nhiều user để đảm bảo performance, latency và network bandwidth. Gần ba phần tư các URL được truy cập từ các trang web chỉ được truy cập một lần và không bao giờ được truy cập lại. Việc cache lại các content này là không cần thiết và lãng phí tài nguyên hệ thống. Một ứng dụng quan trọng của Bloom Filter là việc sử dụng chúng một cách hiệu quả để xác định content nào nên được cache. Để ngăn chặn cache các content chỉ được truy cập một lần, một Bloom Filter được sử dụng để theo dõi tất cả các URL được truy cập bởi người dùng. Content được cache chỉ khi nó đã được truy cập ít nhất một lần trước đó, tức là content chỉ được cache khi có ít nhất 2 request tới nó. Việc loại bỏ những content chỉ được truy cập một lần tiết kiệm đáng kể bộ nhớ, tăng tỉ lệ hit rate.
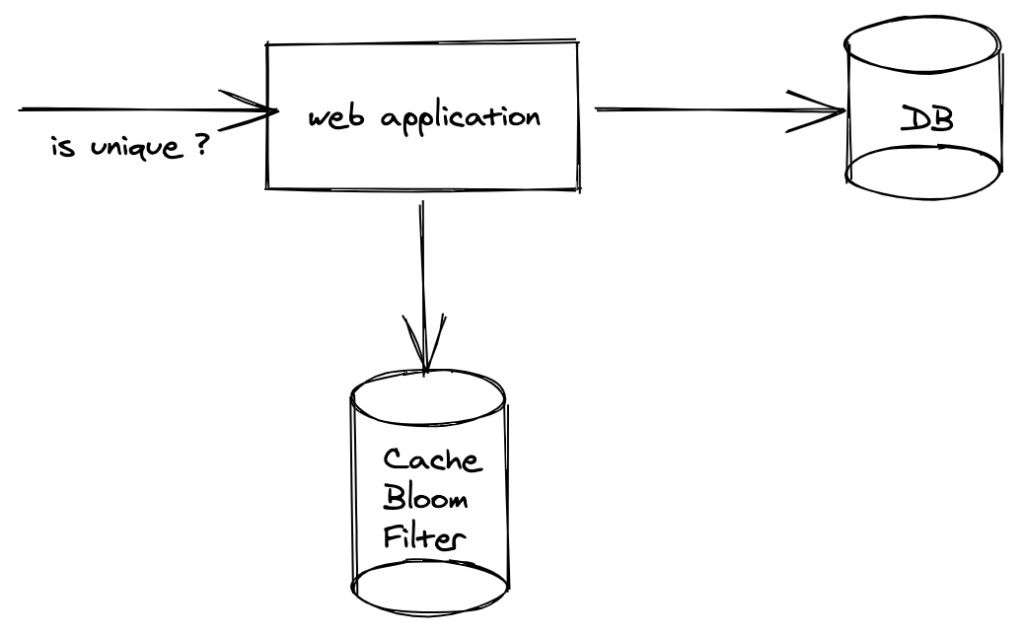
Kiểm tra password yếu
Ngày nay việc đặt password yếu là sẽ dẫn đến nhiều rủi ro. Attacker có thể dễ dàng brute force trên tập password hay được đặt hoặc tập password đã bị leak để chiếm tài khoản. Ý tưởng của việc này là lưu một tập dữ liệu bao gồm các password yếu và check match khi user đặt password. Việc này có thể được check nhanh chóng bằng Bloom Filter, nhanh như hash map nhưng lại tốn ít space hơn. Dễ dàng hoạt động trên tập data lớn.
Ứng Dụng trong Mạng Xã Hội và Quảng Cáo
Các công ty hoạt động trong mạng xã hội và quảng cáo có thể sử dụng Bloom Filter để kiểm tra xem một người dùng hoặc một quảng cáo đã xuất hiện trước đó hay chưa, để tránh hiển thị nội dung trùng lặp.
Nhiều công ty lớn đã áp dụng Bloom Filter để xử lý cho các bài toán của họ:
- Akamai CDN dùng Bloom Filter để loại bỏ các request một lần đến disk cache. Akamai cũng là công ty phát hiện ra rằng gần 75% request từ user đến server của họ chỉ được đọc một lần.
- Google BigTable, Apache HBase, Apache Cassandra và cả PostgreSQL đều dùng Bloom Filter để kiểm tra content có tồn tại không trước khi query vào disk. Giảm disk lookups và tăng đáng kể hiệu suất query.
- Google Chrome browser đã từn dùng Bloom Filter để check những ỦL độc hại. Tất cả URL được check ở Bloom Filter local trước khi được gọi.
Lời kết
Bloom Filter đã trở thành một công cụ mạnh mẽ trong xử lý dữ liệu và giúp giải quyết nhiều vấn đề về hiệu suất và bộ nhớ trong các ứng dụng thực tế. Các công ty lớn và tổ chức trên khắp thế giới đã sử dụng Bloom Filter để cải thiện dịch vụ và tối ưu hóa xử lý dữ liệu của họ. Hy vọng qua bài viết này bạn có thêm công cụ để giải quyết các bài toán sau của mình. (Thay vì HashMap =))